联邦学习:保护数据隐私的机器学习新方法及其应用场景解析
trust 2025年1月19日 10:07:42 trustwallet安卓版下载 300

在数字时代,数据隐私与共享的冲突日益加剧,联邦学习应运而生,成为破解这一难题的关键。它既保障了隐私安全,又实现了数据的协同利用。
联邦学习的诞生背景
在当前隐私保护意识增强的时代,传统机器学习数据处理方法遭遇了严重挑战。以欧盟2018年实施的《通用数据保护条例》为例,该条例对数据隐私保护设定了严格的标准,一旦数据集中处理出现失误,就可能触犯规定。在此背景下,联邦学习作为一种新方法应运而生,它不依赖数据集中处理,从根本上消除了这种风险。此外,众多企业意识到数据的重要性,不愿轻易放手数据控制权,而联邦学习恰好能够满足他们在数据控制与价值挖掘之间的平衡需求。
在实际情况里,众多知名科技公司纷纷尝试这种做法。比如谷歌,它已经开始研究联邦学习在自家多款产品中的应用。这样做的目的是既能充分利用用户数据,又能遵守隐私保护法规,避免引起用户对隐私问题的顾虑。
联邦学习的独特定义与目标
联邦学习与常规机器学习有所不同,其核心在于多个分散的节点各自利用自己的数据集来训练机器学习模型。比如,一个掌握多所学校数据的培训机构,若想基于这些数据构建一个预测学生成绩的模型,但又不愿泄露校际间的数据,便可以采用联邦学习的方式。在这种模式下,每所学校作为一个独立的节点,独立使用自己的数据来训练模型。
目标十分清晰。从数学层面来说,就好比是调整一个目标函数,目的是让所有参与客户端的模型权重趋向于一个统一的模型。具体到实际应用,比如在智能家居环境中,各种智能设备,比如智能冰箱和空调,它们的目标是共同打造一个节能优化的模型。每个设备都会利用自己的数据,以提升整个节能优化模型的效果。
联邦学习的分类情况
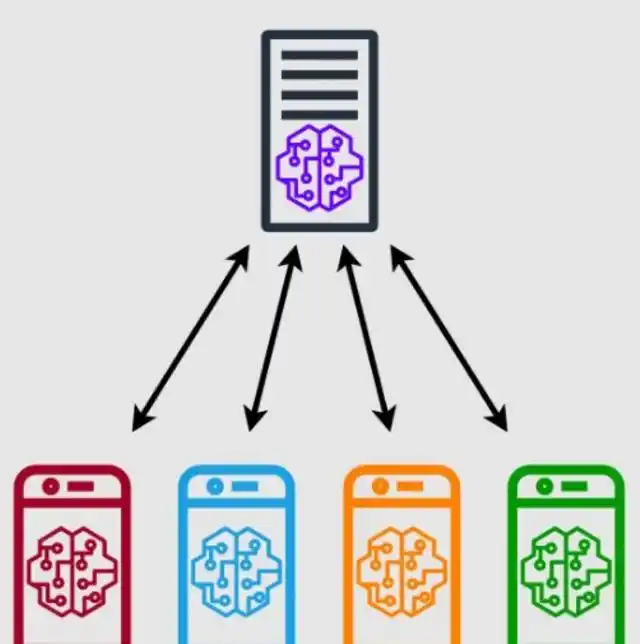
集中式联邦学习相对比较容易理解。在它的工作模式中,中央服务器负责管理所有事务,比如挑选训练的成员、合并模型更新等。以手机系统更新中的模型优化为例,中央服务器相当于系统端,而众多手机则是参与者。系统端负责协调这些手机内容参与训练。但在此过程中,如果系统端出了问题,就会对整个训练过程造成影响。
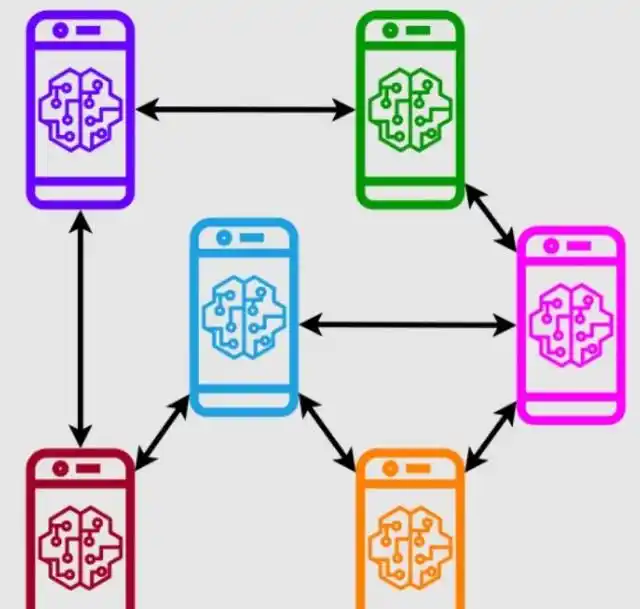
去中心化的联邦学习有其独特之处,每个节点独立完成协调任务,共同构建全局模型。以分布式区块链节点为例,若运用联邦学习,便能实现去中心化的学习模式。尽管网络结构较为复杂,但其灵活性较强,还能防止单一节点故障。在异构联邦学习中,面对多种不同的客户端,效果显著。比如在物联网应用中,手机与智能家居设备的计算和通信能力各异,利用HeteroFL框架,便能在此异构环境中精确构建全局推理模型。
联邦学习的一般流程
首先,我们要明确模型定义。这就像开发一款新的图像识别程序,首先要决定识别的对象是什么。这就是所谓的模型定义。接下来,我们进行本地数据训练。比如,某个电商平台的不同区域会使用自己的数据来训练预测用户购买行为的模型,这个过程就叫做本地数据训练。
然后进行参数整合。就像众多研究机构对同一种疾病的若干相关基因进行探究,各自取得一些成果后,再将这些参数合并。最终模拟各方参与者的训练过程,并综合模型参数。这就像一个跨地区的连锁店,将各区域的数据收集起来,进而调整整体的营销策略模型。
联邦学习的简单代码示例
在Python中,实现联邦学习的示例并不繁杂。比如,我们可以先设定模型变量的初始值,就好比为训练猫狗识别的卷积神经网络设置参数。接着,在各个本地环境中,使用数据来计算各自的模型参数。比如,用一家宠物医院的数据来提升猫狗识别的准确性,再用另一家宠物医院的数据来进一步优化准确性。最后,按照既定的计算规则,比如平均或加权,将不同本地计算出的模型参数合并。
联邦学习的应用场景很广
医疗界中,各家医院都保存着独有的病例资料。以糖尿病研究为例,由于涉及患者隐私,这些数据通常不便于共享。然而,通过联邦学习技术,我们可以共同培养一个用于预测糖尿病并发症的模型。
在金融领域,当银行与银行或金融科技公司共建反欺诈系统时,涉及众多客户资料,虽不能相互泄露,却可携手合作,确保客户财务信息不被泄露,并提升反欺诈系统的效能。
在物联网领域,各种设备比如智能门锁和智能摄像头需要增强其安全性能的预测模型。然而,这些设备将数据传输至中心服务器时存在安全隐患。采用联邦学习技术则能有效应对这一问题。
你觉得联邦学习在哪个行业前景最为广阔?期待你的点赞、转发,也欢迎在评论区展开讨论。
Trust Wallet以其强大的功能、安全性以及用户友好的界面,成为众多加密货币用户的首选钱包。无论是新手还是老手,都能在Trust Wallet中找到适合自己的管理方式,为数字资产的管理提供了极大的便利。通过这款钱包,您可以轻松、安全地掌握自己的加密资产。